
Serverless and data stack (3) -- analytics pipeline
A simplified version of "Emerging Architectures for Modern Data Infrastructure" from A16Z blog

We briefly talked serverless cloud data warehouse by going through an academic paper written by the Snowflake team in one previous post. But building an end-to-end data analytics solution is more than just data warehouse — it is a long pipeline together to show the value to the non-technical stack holders.
Now it’s natural to ask “then can we build the end to end data analytics pipeline in a ‘serverless’ way?” In other words, can we build a data analytics pipeline with the following benefits?
without upfront capacity planning (so that the infrastructure scales without our concern)
without managing the building blocks up-time ourselves (so that we don’t need to build various HA mechanisms)
What may a typical data analytics pipeline look like nowadays?
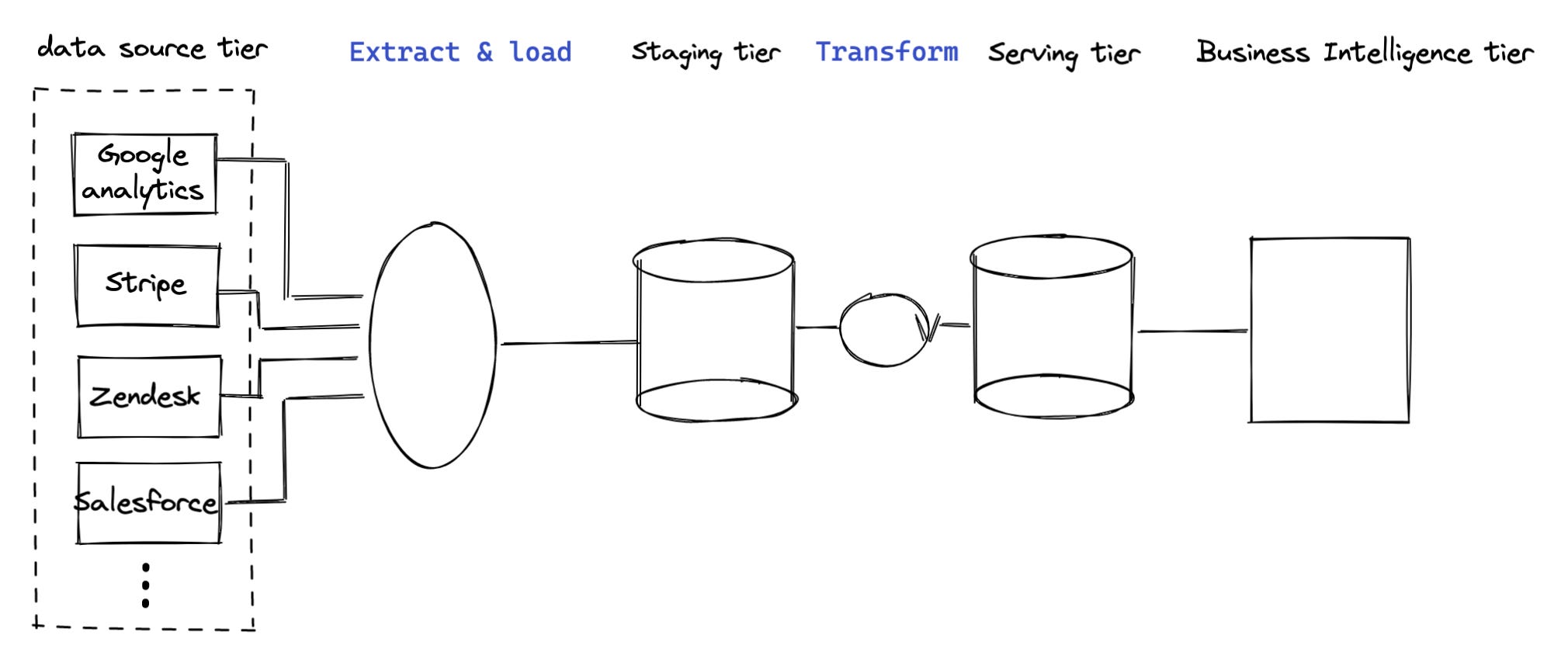
Here is a quick and brief explanation of the above pipeline diagram:
Nowadays, an analytics pipeline needs to being able to analyze data across multiple data sources;
And because of the inexpensive storage cost structure of modern cloud data warehouse, we typically do the Extract + Load (“EL”of the ELT) so that all the data from the sources are loaded into our cloud data storage tier (“staging tier”)
And then we do the transformation (“T” of the ELT) from the staging tier to the serving tier;
serving tier is the data that is ready for final consumption by business intelligent tools.
Concrete implementations of the above data pipeline

If we look at the chosen building blocks in this pipeline diagram, we can build an end to end data analytics pipeline without concerning the HA and infrastructure side of the story, without concerning the capacity planning upfront. With ELT cloud services like Fivetran, cloud data warehouse services like Bigquery and Snowflake, cloud business intelligent services like Looker, we can build an end to end data analytics pipeline without managing our own infrastructure.
NOTE: Fivetran is a cloud product to help us to do the ELT processing. Its price model is not an ideal “serverless” because it is not “Zero upfront cost commitment” as we defined in our pricing model for a “serverless” building block.
“Modern stack” in a data pipeline from A16Z’s viewpoint
The reason I wrote this post is that I read a blog post from A16Z talking about “modern data stack”. I personally think a modern data stack ought to give users really low friction to start experimenting with (i.e., “Every one and every org can build their data stack”), and a majority of the stacks mentioned in that post do fall into my criteria. Though it talks from an investor viewpoint, it gives a structural way to look at the steps in a data analytics pipeline.

I felt I’d like to share (with my personal hands-on experience) that it’s not super expensive building the initial PoC with these “serverless” building blocks — i.e., “Every one and every org can build their data stack”.
Closing note
Hopefully this post gives you one example about how a data analytics pipeline can be built in a light weight manner, and you don’t need an army of data infrastructure engineers as the prerequisite of starting your project.